Architecting Robust ETL Workflows Using PySpark in Azure
Creating an ETL workflow is one of the first practical tasks you will undertake as a beginner in data engineering. The process of moving and cleaning data before it is prepared for dashboards or analysis is known as extract, transform, and load, or ETL.
This article will show you how to use PySpark on Azure to set up and arrange ETL pipelines. Even though these tools seem large at the moment, don’t worry. You’ll see how they complement one another and why each data team uses them by the end.
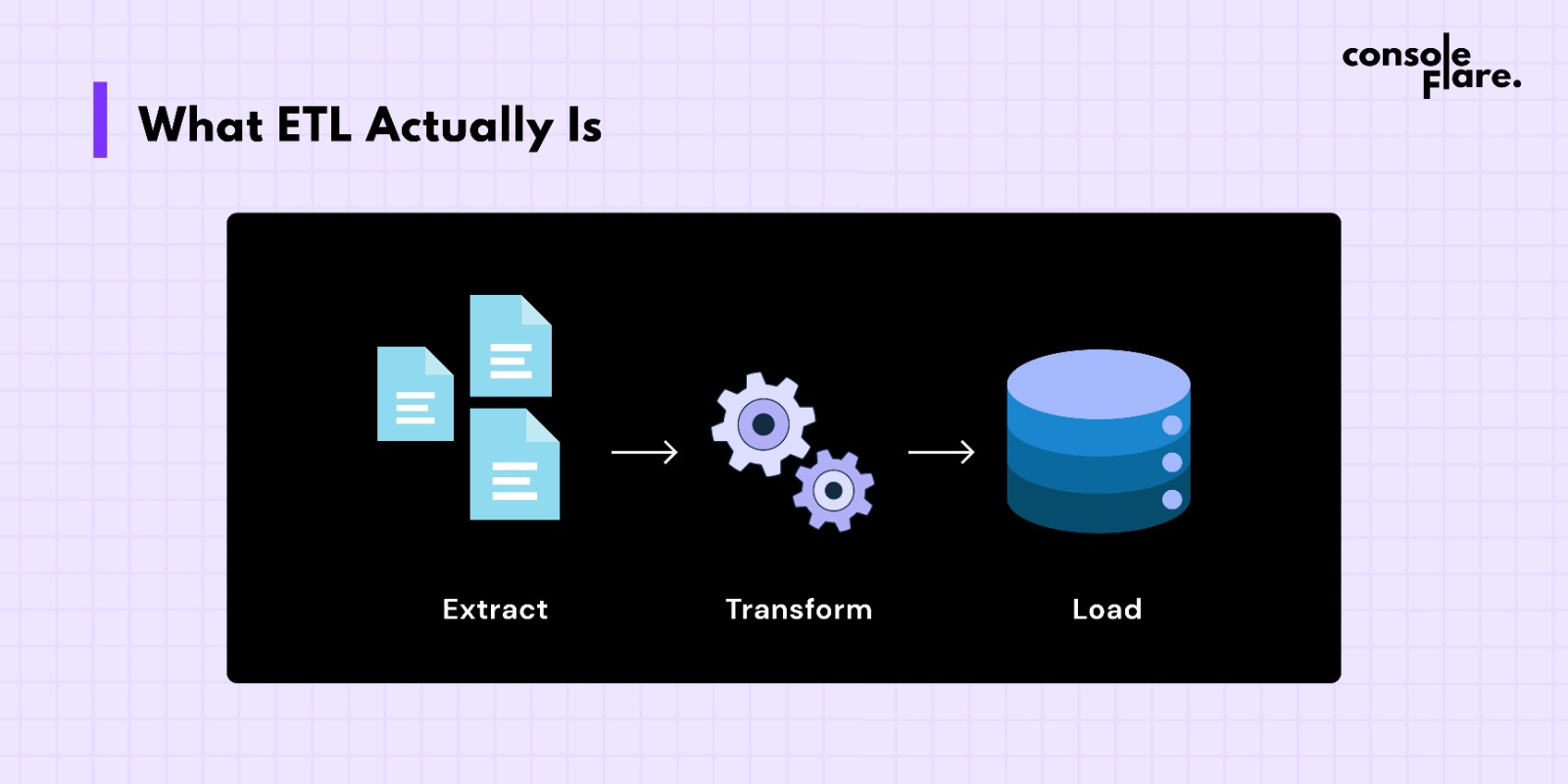
What ETL Actually Is
Let’s simplify it:
Extract: Retrieve the unprocessed data from its source. It could be an API, database, or file.
Transform: Make the data clean and usable by fixing, filtering, or enriching it.
Load: Put the finished version in a dependable location, such as a data lake or database.
In order to maintain current data for your dashboards or reports, you will execute ETL jobs on a daily or hourly basis.
Why Azure and PySpark Get Along So Well
The Python interface for Spark is called PySpark. It enables you to write straightforward Python code to handle massive volumes of data that are too big to fit in a single machine’s memory.
In contrast, Azure provides you with tools that make managing this entire setup simple. Networking, servers, and clusters are not issues for you. You can leave that to services like Azure Databricks, Data Lake, and Data Factory.
When combined, they give data engineering the feel of solving real-world data problems rather than juggling machines.
The Three Levels of an ETL Workflow in PySpark
Three primary layers are present in all ETL pipelines, regardless of size:
1. Take Out the Layer
You gather information from a variety of sources.
As an example:
raw_df = spark.read.csv("/mnt/raw/customers.csv", header=True)Making It on Azure
This is how you would usually set up an ETL on Azure:
- Azure Data Lake Storage is where you keep your unprocessed and processed data.
- Your PySpark code runs on Azure Databricks.
- Azure Data Factory takes care of when and how your ETL jobs run.
A straightforward flow:
- Put your raw files in the Data Lake.
- Make a Databricks notebook that has PySpark changes in it.
- Set it up to run every day in Data Factory.
- Send the output back to Data Lake or Azure SQL Database.
This setup can handle both small daily tasks and large amounts of data at once.
How to Write Your First ETL Job in PySpark
In Databricks, a simple PySpark job looks like this:
A quick overview:
Your Spark app starts with the SparkSession.
- .read.csv() gets data from a CSV file.
- .dropna() takes out bad rows.
- .filter() keeps transactions that are okay.
- The cleaned data is saved by .write.parquet().
You can use any of these methods on distributed data, so you can handle millions of rows with little code.
The Best Ways to Get Started
- Maintain a tidy folder structure. Keep the final, transformed, and raw data separate.
- Verify your data before writing it.
- Keep track of your job executions and save error messages for troubleshooting.
- For improved performance, use Parquet or Delta formats.
- Store paths and secrets in environment variables or Azure Key Vault instead of hardcoding them.
- Before scaling, test everything on a small dataset.
You’ll be glad you started these habits early.
How to Keep an Eye on and Enhance Your Work
Utilize Azure’s resources:
- The Databricks Job Runs View displays failures and execution history.
- Azure Monitor keeps tabs on cluster expenses and performance.
- Regularly review the logs. Spark tells you where and what went wrong.
Consider caching, partitioning, or adjusting the size of your cluster if your job seems to be running slowly.
Final Remarks
It takes some setup to learn how to create ETL workflows in PySpark on Azure, but the effort is worthwhile. You’ll learn about the flow, cleaning, and operation of actual analytics systems.
Begin in modest steps. Try some things out. You’ll be prepared to manage pipelines at the production level once you’re comfortable with a few small tasks.
Concluding
Developing robust ETL workflows in PySpark on Azure provides the groundwork for managing data as a true data engineer. Building scalable pipelines that meet actual business needs, automating data movement, and guaranteeing data quality are all possible with the correct configuration.
Using practical, industry-level projects, we at Console Flare teach professionals and students how to work with PySpark, Azure, and modern ETL tools with confidence. You can master the entire data engineering ecosystem with our courses, from data ingestion to automation and transformation.