Best Practices for Data Partitioning and Optimization in Big Data Systems
The goal is to help you understand how big data platforms benefit from proper structure, file layout, and optimization steps. Each section supports Best Practices for Data Partitioning and Optimization in Big Data Systems.
Large CSV files often create issues during processing.
- Wrong data types, for example, Aadhaar turning into scientific notation
- Slow queries because Spark scans all files
- Many small Parquet files that reduce read performance
This guide solves all these problems with a simple, end-to-end PySpark flow.
Environment and data
Sample file path: /FileStore/tables/aadharclean.csv
Example columns: IDNumber, Name, Gender, State, Date of Birth.
Step 1: Load the CSV file

Following Best Practices for Data Partitioning and Optimization in Big Data Systems, always inspect your raw file before applying any structure or optimization.: Load the CSV file
df = spark.read.csv(
"/FileStore/tables/aadharclean.csv",
header=True,
inferSchema=True
)
df.show(5)
df.printSchema()
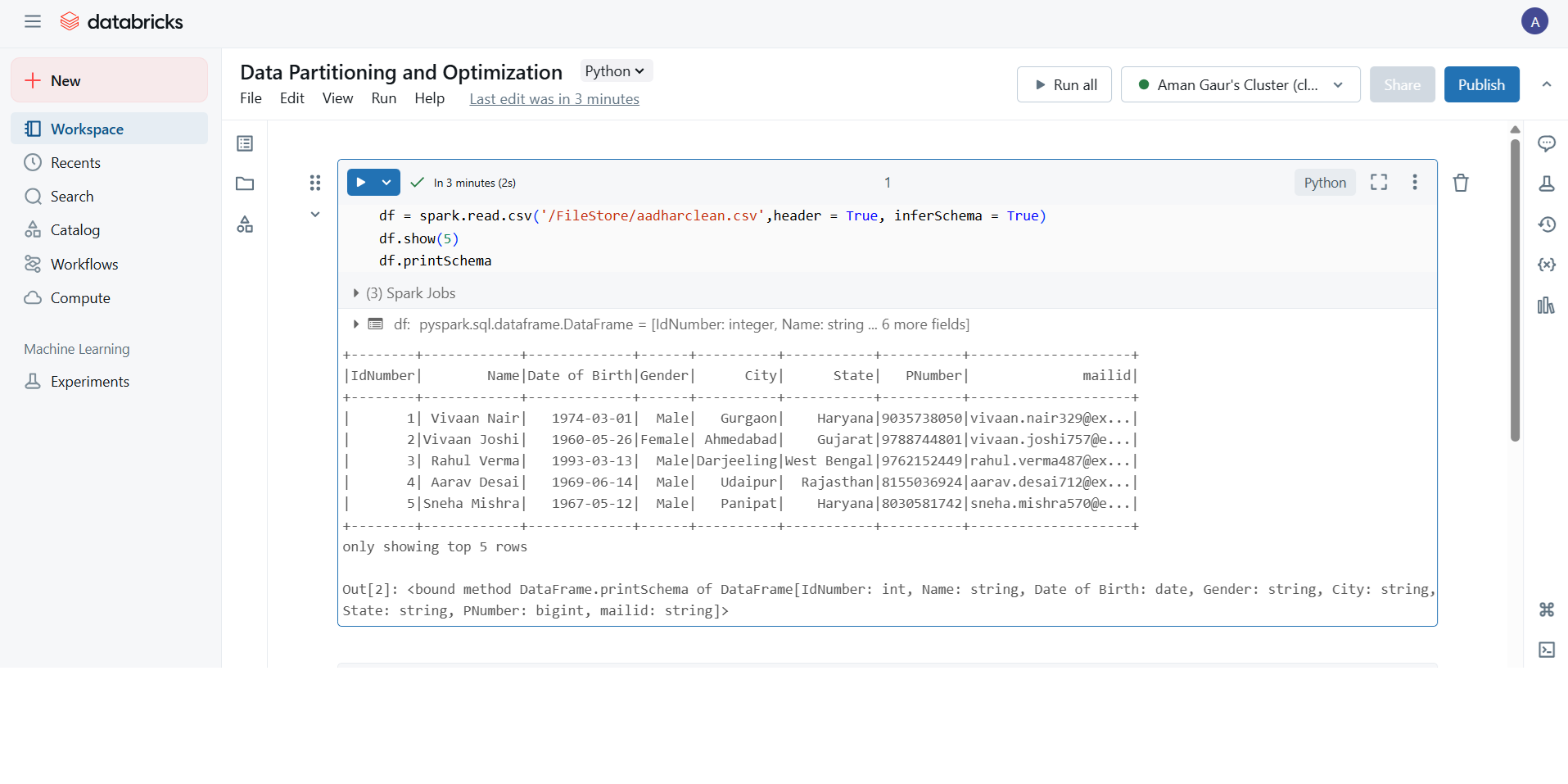
What to check:
show()previews sample rowsprintSchema()shows the inferred data types
If the ID Number appears as a float or scientific notation, fix it in the next step.
Step 2: Clean the schema and cast the ID column

ID should stay as text. The numeric format removes leading zeros and changes the value format.
from pyspark.sql.functions import col
df = df.withColumn("IdNumber", col("IdNumber").cast("string"))Why this matters:
- ID Number stays accurate
- Grouping and joining using ID Numbers gives correct results
Step 3: Write data with partitions
Best Practices for Data Partitioning and Optimization in Big Data Systems recommend choosing stable and filter-friendly columns.: Write data with partitions
Partitioning improves query speed. Choose columns that filter well. In the sample screenshot, Gender and State are suitable.
df.write.mode("overwrite") \
.partitionBy("Gender", "State") \
.parquet("/FileStore/tables/aadhar_partitioned")
Resulting folder structure:
/aadhar_partitioned/Gender=Male/State=Punjab/...
/aadhar_partitioned/Gender=Female/State=Goa/...
Benefit:
Spark reads only the partitions that match your filter.
Step 4: Read the partitioned data
df_part = spark.read.parquet("/FileStore/tables/aadhar_partitioned")
df_part.show(10)
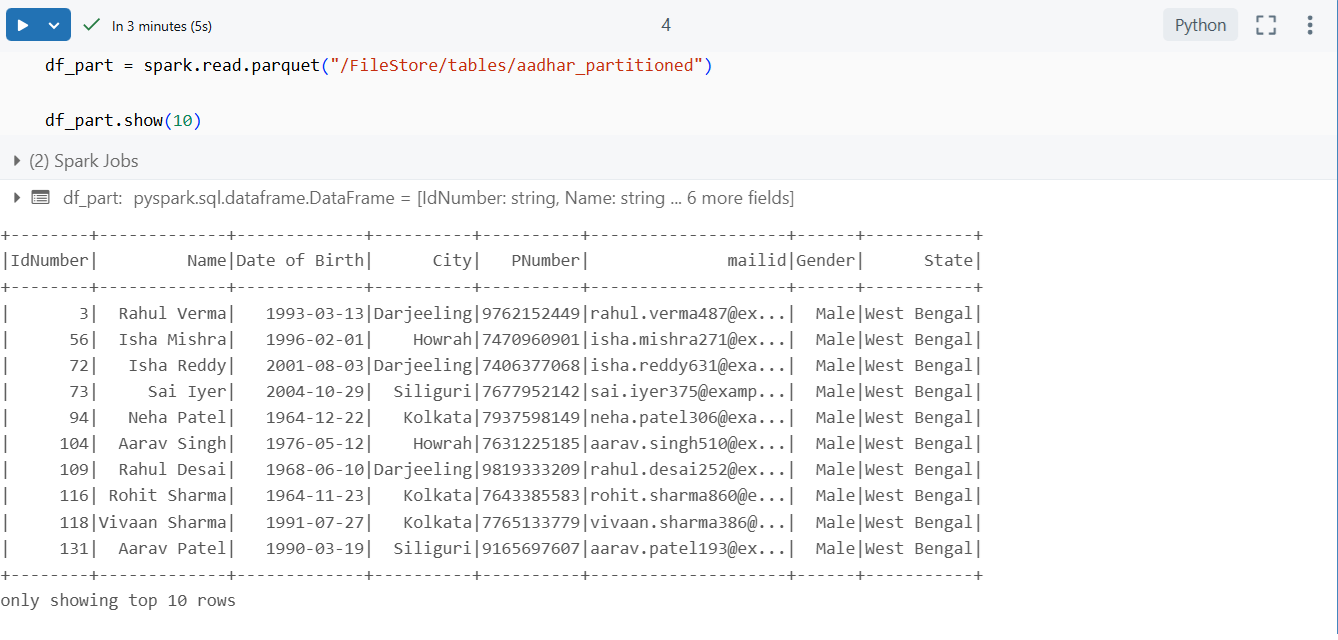
This validates the write operation and confirms the folder structure.
Step 5: Enable Parquet compression
Parquet already improves speed. Compression reduces storage and IO.
spark.conf.set("spark.sql.parquet.compression.codec", "snappy")
Why Snappy:
- Fast compression
- Low CPU cost
- Widely used with Parquet
Step 6: Compact small files

Avoiding too many tiny files improves scan performance.: Compact small files
Small files slow down queries. Compact them using coalesce.
df_part.coalesce(10).write.mode("overwrite") \
.parquet("/FileStore/tables/aadhar_partitioned_optimized")
Notes:
coalescereduces partitions without full shuffle- Use
repartition(n)If you need a balanced shuffle
Step 7: Sort data within partitions
Sorting supports Best Practices for Data Partitioning and Optimization in Big Data Systems by improving compression and range filtering.: Sort data within partitions
Sorting improves compression and range query performance.
df_sorted = df.orderBy("Date of Birth")
df_sorted.write.mode("overwrite") \
.partitionBy("Gender", "State") \
.parquet("/FileStore/tables/aadhar_partitioned_sorted")
Tip:
Use sorting when you frequently query using date ranges or numeric ranges.
Full end-to-end code
# Load CSV
df = spark.read.csv(
"/FileStore/tables/aadharclean.csv",
header=True,
inferSchema=True
)
from pyspark.sql.functions import col
# Clean Aadhaar column
df = df.withColumn("Aadhaar Number", col("Aadhaar Number").cast("string"))
# Write partitioned output
df.write.mode("overwrite") \
.partitionBy("Gender", "State") \
.parquet("/FileStore/tables/aadhar_partitioned")
# Read back
df_part = spark.read.parquet("/FileStore/tables/aadhar_partitioned")
# Enable compression
spark.conf.set("spark.sql.parquet.compression.codec", "snappy")
# Compact files
df_part.coalesce(10).write.mode("overwrite") \
.parquet("/FileStore/tables/aadhar_partitioned_optimized")
# Sort inside partitions
df_sorted = df.orderBy("Date of Birth")
df_sorted.write.mode("overwrite") \
.partitionBy("Gender", "State") \
.parquet("/FileStore/tables/aadhar_partitioned_sorted")
Additional Best Practices for Data Partitioning and Optimization in Big Data Systems

Add these concepts to strengthen your pipeline.
- Keep partition count balanced
- Monitor file sizes
- Use bucketing for repetitive joins
- Enable compression consistently
- Best Practices
- Select partition columns with balanced cardinality
- Maintain practical file sizes, ideally between 100 MB and 1 GB
- Use bucketing for frequent joins
- Use coalesce for fewer files, repartition for better parallelism
Conclusion:
To join this workshop, register yourself on ConsoleFlare, and we will call you back.
Thinking, Why Console Flare?
Recently, ConsoleFlare has been recognised as one of the Top 10 Most Promising Data Science Training Institutes of 2023.
Console Flare offers the opportunity to learn Data Science in Hindi, just like how you speak daily.
Console Flare believes in the idea of “What to learn and what not to learn,” and this can be seen in their curriculum structure. They have designed their program based on what you need to learn for data science and nothing else.
Want more reasons?
Register yourself on ConsoleFlare, and we will call you back.
Log in or sign up to view
See posts, photos, and more on Facebook.